Query reviews (part 1): Overview
The 1st post in the series gave an overview of what a query review is and the value they can bring you. So now let’s talk about how one is done, specifically, how to do a query review using pt-query-digest.
The point of a query review is that it is a comprehensive review of queries. Imagine if you could get a list of all queries that run on your system, and then you systematically looked at each query to determine if it is optimized. That is the basic concept behind a query review.
So, how do you get a list of queries?
pt-query-digest can use a slow query log, binary log, general log or tcpdump. I usually use a slow query log with long_query_time set to 0, so I can capture all the successful queries and their timings. If this is too much overhead, consider using Percona Server’s log_slow_rate_limit and log_slow_rate_type parameters to only log every nth session/query. This means that if you have 5000 queries per second, you can set the slow logging rate to every 100th query, and reduce the write overhead for the slow query log to 50 queries per second (instead of all 5000 queries).
So you have your log, now what? Well, we need to process it. The –type option is where you set what your log type is (binlog, genlog, slowlog, tcpdump). Default is slowlog.
By default, pt-query-digest will give you a report of the top 95% worst queries. You can change that with the –limit parameter – note that –limit just limits the output; pt-query-digest still processes all the queries in the log file. If –limit is followed by an integer, it will limit the output to the top X queries; if it’s followed by a percentage (e.g. 10%) it will output the top percentage of queries.
As this is a query review of all queries, we will want to set the limit to 100%.
There are a lot of other options that pt-query-digest has, but many of them are there so we can distill and get queries that meet a certain criteria. The point of a query review is to look at ALL queries, so we do not need to use those options.
In fact, the only other options we need are related to the review itself. Because a review is systematic, we need a place to store information related to the review. How about a database for that? In fact, pt-query-digest has a –review option that takes parameters to store the information into a table.
Here is the command I recently used to start a query review. It was run from the shell commandline, and I used –no-report because I did not want anything other than the table and its rows created:
[sheeri.cabral@localhost]$ pt-query-digest --no-report --type slowlog --limit 100% --review h=localhost,u=sheeri.cabral,D=test,t=query_review --create-review-table --ask-pass mysql_slow.log
You can see that –review has a number of arguments, comma-separated, to identify a table on a host to put the queries into. I used the –create-review-table flag to create the table, since it did not already exist, and –ask-pass because I do not type in passwords in a shell command.
pt-query-digest then spends some time analyzing the file then creating and populating the table. Here’s a sample row in the table:
*************************** 1. row ***************************
checksum: 11038208160389475830
fingerprint: show global status like ?
sample: show global status like ‘innodb_deadlocks’
first_seen: 2017-06-03 11:20:59
last_seen: 2017-06-03 11:32:15
reviewed_by: NULL
reviewed_on: NULL
comments: NULL
The checksum and fingerprint are ways to make the query portable, no matter what values are used. The fingerprint takes out all the differences among iterations of the query, and puts ? in its place. So if you have a query that’s used over and over, like
SELECT first_name FROM customers WHERE id in (1,2,3)
the fingerprint would look like
SELECT first_name FROM customers WHERE id in (?+)
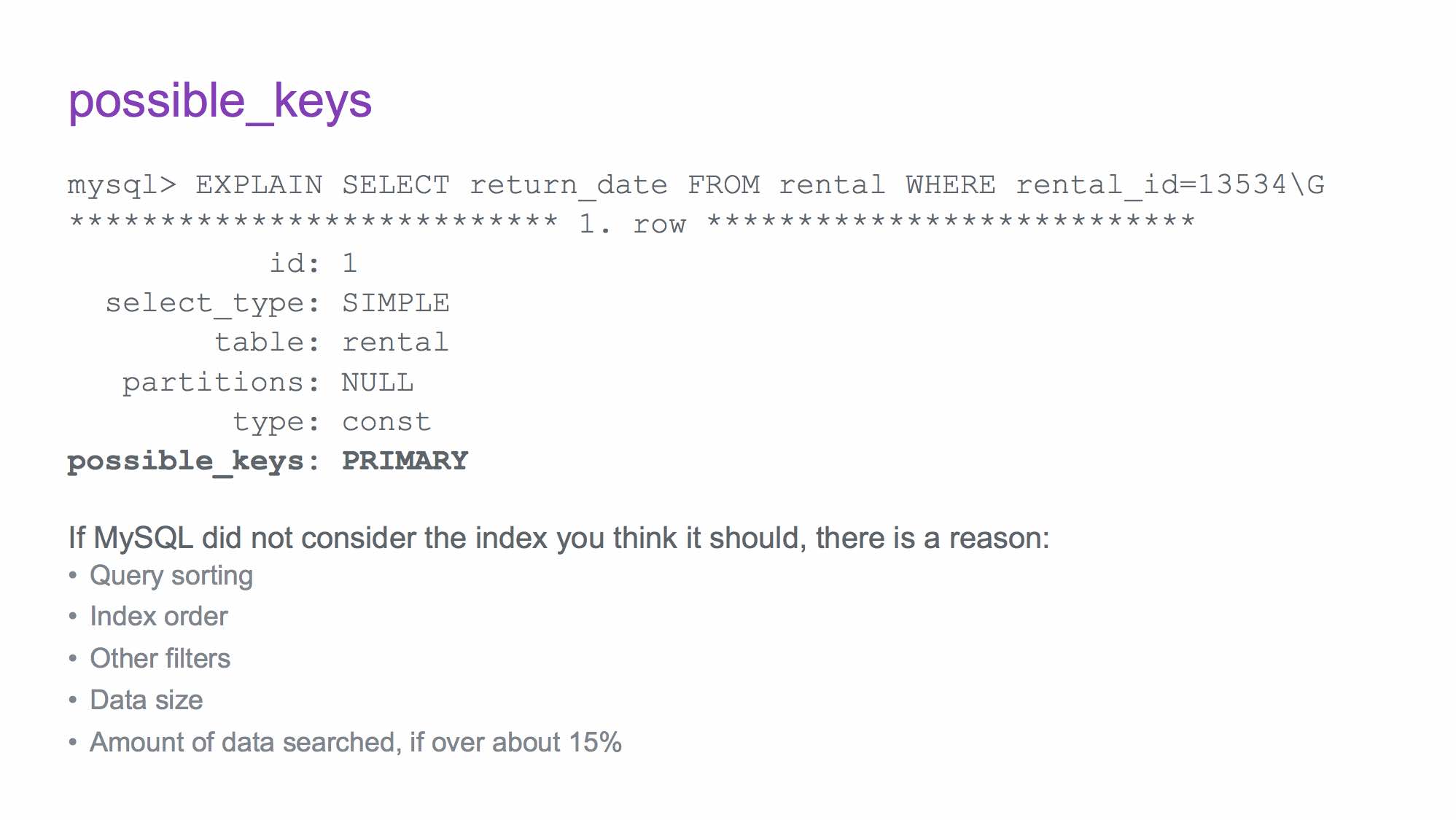
The sample provides a way for us to copy and paste into an EXPLAIN (or my favorite, EXPLAIN FORMAT=JSON) statement, so that we can assess the query.
So then we can go through the process of optimizing the query. In the end, this query has nothing to tweak to optimize, so I update the reviewed_on date, the reviewed_by person, and the comments:
mysql> UPDATE test.query_review set reviewed_on=NOW(), reviewed_by='sheeri.cabral', comments='no mechanism to optimize' WHERE checksum=11038208160389475830;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
On to the next query – we shall get the next query that has not yet been reviewed:
mysql> select * from test.query_review where reviewed_on is null limit 1\G
If you have already done some query reviews, your WHERE clause may look something like where reviewed_on is null OR reviewed_on < NOW()-interval 6 month.
And then look at that query for optimization. Lather, rinse, repeat. This is a GREAT way to get familiar with how developers (and ORMs) are writing queries.
Some tricks and tips – first take a look at all the queries less than 50 characters or so – you can easily update those to be all set to reviewed, with whatever message you want.
mysql> select fingerprint from query_review where length(sample)<50;
+----------------------------------------------+
| fingerprint |
+----------------------------------------------+
| administrator command: Ping |
| set session `wait_timeout` = ? |
| show tables |
| rollback |
| select * from information_schema.processlist |
| select @@session.tx_isolation |
| show status |
| start transaction |
| select user() |
| show query_response_time |
| set autocommit=? |
| show full processlist |
| show databases |
| administrator command: Statistics |
| show plugins |
| show slave status |
| commit |
| set names ? |
| show global status like ? |
| administrator command: Quit |
| show /*!? global */ status |
| set names utf? |
| select @@version_comment limit ? |
| show engine innodb status |
| select database() |
+----------------------------------------------+
25 rows in set (0.00 sec)
One great feature is that you can add columns to the table. For example, maybe you want to add an “indexes” column to the table, and list the index or indexes used. Then after the query review is complete, you can look at all the indexes in use, and see if there is an index defined in a table that is NOT in use.
You can review all the queries and run a query review every 6 months or every year, to look at any new queries that have popped up, or queries that have been removed (note first_seen and last_seen in the table).
You can also see how the query performance changed over time using the –history flag to pt-query-digest, which can populate a table with statistics about each query. But that is a topic for another post!
Query reviews are excellent ways to look comprehensively at your queries, instead of just the “top 10” slow, locking, most frequent, etc. queries. The EXPLAINing is long and slow work but the results are worth it!